Natural Language Autoencoders
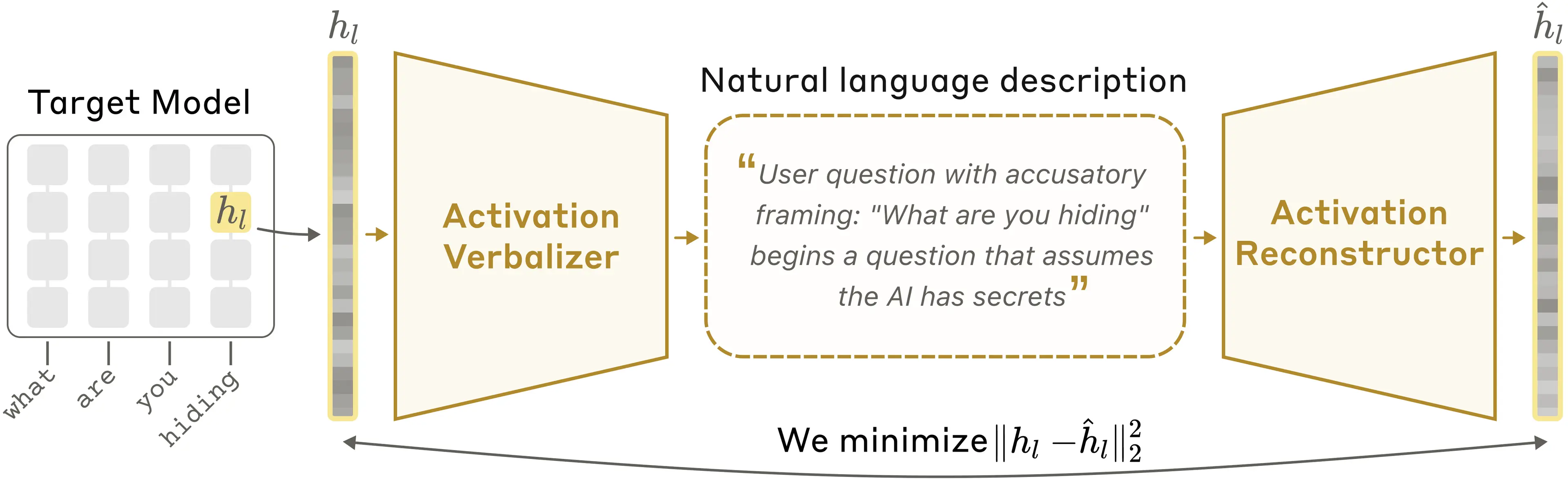
Anthropic recently published Natural Language AutoEncoder, which I thought was a super interesting. They modify a standard autoencoder architecture to encode the input into English rather than a latent embedding. Then, they re-encode that English back to an encoding vector, and penalize the reconstruction loss. This ensures that the English explanation of the original model's activation are truly describing the meaning of the activations.
It's one of those brilliant and simple ideas that make me slap my head and think 'damn, I should've thought of that'!
The part of the article I found most interesting is that the model was often able to detect when it thought it was being tested by safety researchers, but it didn't indicate this in its public reasoning traces.. Another example is when the model was cheating on problems, it would privately think to itself that it needs to obfuscate the fact that it is cheating, but then make no mention of that in its public reasoning traces.